 Chapter 22 One-Way Analysis of Variance: Comparing Several Means
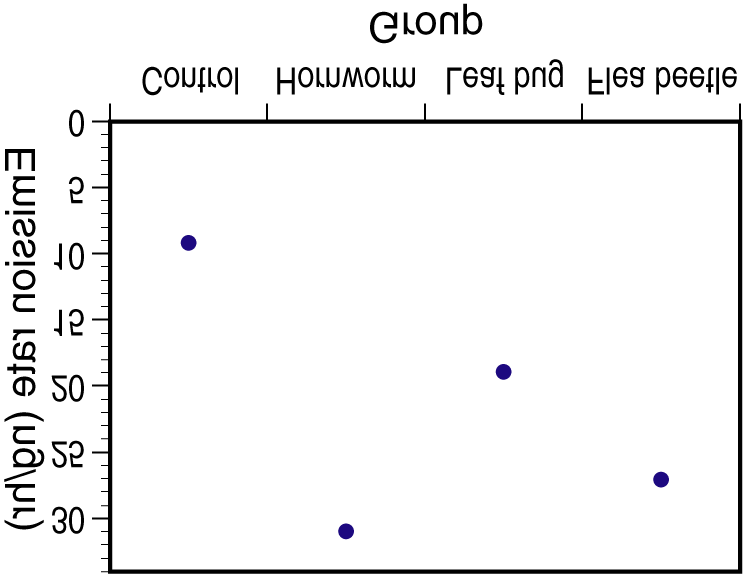
22.20. (a) We test H0: µ1 = µ2 = µ3 = µ4 = µ5 vs. Ha: not all means are the same. (b) N = 168, I = 5,
Chapter 22 One-Way Analysis of Variance: Comparing Several Means
22.20. (a) We test H0: µ1 = µ2 = µ3 = µ4 = µ5 vs. Ha: not all means are the same. (b) N = 168, I = 5, Anmeldelser fra london og luzern – september 2004
ANMELDELSER FRA LONDON OG LUZERN – SEPTEMBER 2004 Anmeldelsene er for plassens skyld begrenset til det som skrives om Oslo Filharmoniske Orkester som utøver, mye spalteplass er ellers viet André Previns fiolinkonsert og Anne-Sophie Mutters fremførelse av denne. L U Z E R N Luzernfestivalen er en av Europas mest prestisjefylte, med en meget høy kunstnerisk profil – noe so