APPENDIX TO THE C-ORAL-ROM QUARTERLY REPORT January-March 2002 APPPENDIX 1 Assessments for comparability within the multilingual corpora: notes to be added to the C-ORAL- ROM sampling structure and textual format Sampling Problems The difficulties with authorization in the public informal field have been the object of discussion in the Madrid meeting. Probably for this reason a set of samples, whose nature is private, has been classed as public in the corpus structure, on the basis of some non-essential feature (for example sometimes private conversations have been classified as public if recorded in a public place). Solution In order to allow the selection of informal texts of a clearly public nature in accordance with present limitations the percentage of words in this field must be reduced to 25.500 words (without prejudice to the meaning of the C-ORAL-ROM resource) with a parallel rise in the Family/private field (keeping the previous Monologue/Dialogue proportion). The following will be the revised corpus structure in the informal part: Family /Private context 124.500 Public context 25.500
Textual Format Problem Many possible interpretations of the information required in the headers appear in the four corpora. Solution The following definition of the headers must be coherently followed in each corpus: Title: one or two words. Not in English but in the sub-corpus language (French, Spanish, etc.) Participant field: it must contain the role which must be intended as the role in the linguistic event (neutral role: participant or intervenient; interviewer vs. interviewee; inquisitor vs. accused; phone caller vs. answerer; seller vs. buyer). When the role in the linguistic event is identical to the profession (teacher vs. student) the neutral role is applied. On the contrary the role of relatives, friendship, acquaintance, etc. (mother, daughter; husband -wife; friends, neighbour, colleague, etc.) must be explicit in the situation field. Place: The toponym (Lisbon) (for media the place is where the company is established) Situation: information about all the following defined set of : a) the recording situation (in the silent studio; in the street; at home; in a shop; at the Faculty, etc.; b) information that helps to define the activity performed during the event (gossip; chat; quarrel; discussion; narration; claim, etc). The neutral case is "talk". The information of the Class field (dialogue, conversation etc.) should not be repeated. c) the roles of the participants (see.above). e.g. gossips between friends at home during the dinner.
For media corpora the situation is the name of the program. Problems The text-sound alignement of WPC requires a set of guidelines and some revision of the trascription format. The relation between alignment and prosodic tagging must be uniform all through each corpus. Solutions Requirements on the transcription format due to the alignment program
1) all tagging signs must be necessarily preceded and followed by a space: e.g. space//space 2) all dialogic turns must be concluded with an empty space (this creates a problem with the previously defined C-ORAL-ROM format. See below). 3) of necessity the three dots . must be three dots (the corresponding single symbol must be excluded) 4) in overlapping the brackets must precede and follow the text immediately: <text> instead of < text > 5)N.B:: no double empty space in the text 6) N.B. symbols are written in the correct way: e.g. "//" is correct while "/ /" is incorrect ; [/] is correct, while [/ ] is incorrect Other clarifications with transcription format
Case 1: *MAR: ha puesto un sofa / *VIS: ah si // *MAR : / una mesa de esas pequenas / *VIS: si // *MAR: / con un armario muy simple // In this first case we have “intersection”: in MAR’s first turn we have one tone unit (not an utterance: the utterance goes on in MAR’s second turn and doesn’t end until MAR’s third turn). We mark this continuation with a slash / at the beginning of MAR’s second and third turns. So, we have end of tone unit, not interruption. We may also have this case with overlapping: *MAR: ha puesto <un sofa> / *VIS: [<] <ah si> // *MAR : / una mesa de esas pequenas / *VIS: si // *MAR: / con un armario muy simple // Case 2:
*MAR: es verdad // <y todavia> *VIS: [<] <si> // *MAR : / estas obsesionada // In this case, « y todavia estas obsesionada » is the same tone unit, so we don’t put a slash at the end of “todavia”. That’s the difference with respect to case 1. Case 3. The empty space at the end of the turn is necessary on all occasions because of Winpitchcorpus, therefore, in the Format it can no longer signal out interruptions. Therefore the empty space signalling interruption in the C-ORAL-ROM format must be substituted with a specific sign at both levels of transcription. For example: *MAR: es verdad // <y todavia> + *VIS: [<] <si> // *MAR : obsesionada // The XML conversion program and the Macro prepared in Florence will be up dated with respect to the previous requirement. Clarification as regards the relation between prosodic tagging and the alignment unit: Each C-ORAL-ROM corpus must be aligned only with respect to perceptively relevant terminal contours in order to give rise to a data base of utterances (See the Annex: a) Alignment per utterance; b) terminal contours/utterance rough equivalence). This criterion must be strictly followed in both formal and informal speech, even if the alignment unit frequently turns out a huge textual unit in the formal corpora. Given the importance of this requirements in order to reach the objectives of C-ORAL-ROM, the validation of comparability of the four corpora with respect to the tagging of terminal contours will be expected to meet a more strict criterion with respect to non terminal contours (e.g. agreement of four competent speakers in 90% vs 75% of the selected cases). An important result of the meeting must be stressed. A selection of different contexts of prosodic parsing has been verified through the Italian, Portuguese and Spanish corpora, with special attention to the representation in the three corpora of the main critical contexts. In all relevant cases considered, the perceptively relevant breaks in the speech flow are coherently perceived by Italian, Spanish and Portuguese speakers in the full set of Romance corpora, despite the different syllabic structure of the three languages and the respective lack of competence. Advices for starting WP3 on alignment
a) Alignment must be performed on TXT files. b) Practice with alignment of brief dialogues c) Start real alignment operations with 1.500 words texts. d) Start with monologues e) Before alignment: pass texts trough the XML conversion (Madrid) and through the
verification macro (Florence) to tests correctness with respect to the format
APPENDIX 2 Meetings
Meeting with advisors LABLITA, Italian departement, University of Florence, February 18 – 19, 2002.: Corpus Assessment and the exploitation of the C-ORAL-ROM deliverables with related workshop: “Corpus Linguistics and contrastive research on the C-ORAL ROM corpus” February 18, Morning session
Claire Blanche -Benveniste (Ecole Pratique des Hautes Etudes) Quelqu’un, quelque chose, quelque part, quelque fois Fernanda Bacelar do Nascimento (Centro de Linguistica da Universidade de Lisboa) Un outil pour létude des faits de grammaticalisation: les concordanciers Emanuela Cresti (Università degli Studi di Firenze) La personne verbale dans l’italien parlé
February 18 Afternoon session Paola Gramigni (Università degli Studi di Firenze) Les corpus Lablita. Une analyse comparative. Valentina Firenzuoli (Università degli Studi di Firenze) A corpus based study on variation of illocution: some intonational contours Sabrina Signorini (Università degli Studi di Firenze) Syntactic features and frequency of topic unit: analysis of a sample of italian spoken language Daniela Giani (Università degli Studi di Firenze) Le discours direct rapporté dans le corpus C-ORAL-ROM
February 19 Morning session
Dominique Willelms (Ghent University) Le dictionnaire contrastif des valences verbales Antonietta Scarano (Università degli Studi di Firenze) Les relatives dans l'italien parlé. Étude sur corpus Claire Blanche -Benveniste (Ecole Pratique des Hautes Etudes) L’éspace occupé par les chaînes verbales dans le parlé Massimo Moneglia – Alessandro Panunzi (Università degli Studi di Firenze) Semantic variations of verbs in the C-ORAL-ROM italian sub-corpus
February 19 Afternoon session
Assessement of the 1.1 1.2 deliverables
C-ORAL-ROM WP3 sheduled workshop : Application of prosodic tagging criteria to the C- ORAL-ROM corpora and alignment through WinPitchCorpus LABLITA, Italian Department 8-9-10 April, 2002
Monday 8 9,30 – 11: The theoretical Framework (with application to Italian examples) 11-13: Critical contexts on the Italian corpus afternoon
15-18: Applications on the romance corpus: cases and problems encountered in tagging the other romance languages (examples verified through Win Pitch Corpus). Tuesday 9 9,30 – 12: Explanation of the alignment method of Win Pitch Corpus 12 – 13:
Alignment restrictions on the C-ORAL-ROM transcription format
afternoon 15 - 18: training of each participant to the meeting in concrete aligning operation Wednesday 10 9,30 – 11 introduction to XML, and the macro to convert C-ORAL-ROM format into an equivalent XML-format 11-13: Macro for counting and standard measures derived from transcription Participants Massimo Moneglia (UFIR.DIT) Emanuela Cresti (UFIR.DIT) Marius Spinu (UFIR.DIT) Carlota Nicolas (UFIR.DIT-UAM) Paola Gramigni (UFIR.DIT) Sabrina Signorini (UFIR.DIT) Antonietta Scarano (UFIR.DIT) Guillermo de la Madrid (LLI.UAM) Manuel Alcantara Plà (LLI.UAM) Fernando Ares Chote (LLI.UAM) Rita Veloso (FUL.CLUL) Sandra Antunes (FUL.CLUL) APPENDIX 3
Report by the advisors on the French Delivery.
Réunion à Florence le 17 février 2002, des gestionnaires du projet CORAL-ROM, Massimo Moneglia, Emmanuela Cresti, Fernanda Bacelar Do Nascimento et de deux des consultants représentant le Advisory Board: Dominique Willems et Claire Blanche-Benveniste.
Les consultants sont préoccupés. Le projet est en péril. Les activités de l’équipe d’Aix ne
répondent pas à ce qui en était attendu. Les responsables italiens du projet doivent se rendre à Luxembourg entre le 15 et le 20 mars prochain et ils doivent pouvoir répondre avec précision de l’état de la contribution de l’équipe d’Aix.
Dans la mesure où l’équipe d’Aix n’a pas pu jusqu’ici engager directement un jeune
chercheur avec les subventions obtenues, il avait été envisagé de faire verser une bourse à un chercheur d’Aix par les partenaires, Florence et Lisbonne. Il faut pour cela demander à Luxembourg un changement du contrat. Luxembourg demandera alors à voir les parties du travail faites jusqu’ici et particulièrement les parties comparables des quatre corpus des quatre équipes espagnole, portugaise, italienne et française. L’équipe française doit pouvoir faire un point précis du travail fait et à faire, avec un calendrier motivé, compte tenu de ses empêchements financiers. Il est compréhensible que l’équipe d’Aix n’ait pas encore pu constituer l’ensemble du corpus, comme les trois autres équipes l’ont fait, mais il est impératif qu’elle montre au moins une partie de ce travail, absolument conforme aux normes adoptées par les autres équipes, et qu’elle prenne un engagement précis, en termes de calendrier et de personnes engagées, pour terminer cette phase.
Les consultants ont dressé une liste des demandes, en l’état actuel des choses.
1. Florence voudrait avoir un contact direct avec les personnes chargées de faire le travail à Aix,
et non seulement avec la personne, José Deulofeu, qui organise ce travail.
2. Florence voudrait également avoir une lettre officielle de Jean Véronis, responsable officiel
du projet pour fournir par écrit le nom de la personne qui est l’authorized contact personn à mentionner à Luxembourg.
3. Le travail envoyé par l’équipe d’Aix doit être impérativement ramené aux formats prévus et
réexpédié à Florence d’ici la fin du mois de février :
format des extraits, avec le nombre exact de mots, conforme aux décisions prises. On peut indiquer (cf. modèle portugais) ce qui est fait et ce qui reste à faire.
Présentation du son des CD conforme aux normes prévues lors des précédentes réunions. La compression MP3 empêche la comparaison.
En-têtes (headers) des extraits à faire selon le modèle adopté par les équipes italienne, espagnole et portugaise, et envoyé à J. Deulofeu le vendredi 15 février. Ces headers doivent être contrôlés en fonction du contenu (Cf. Observations faites par Florence le 21/02, par exemple de ne pas nommer monologue ce qui comporte visiblement quatre participants).
Pour répartir les extraits selon les catégories du « formel » et « informel », on peut s’appuyer à la fois sur les rôles et sur la situation, quitte à mettre une brève explication.
Il est très important de préserver la « comparabilité » des corpus entre les quatre équipes. C’est ce que la Commission va vérifier en tout premier lieu. Des documents ont été confié aux consultants et expédiés aussi directement à J. Deulofeu, pour servir de base à cette nécessité de rendre comparables les travaux.
4. L’équipe d’Aix doit préciser, avant le début du mois de mars :
quelle part du corpus ancien sera récupérée et re-formatée
quelle part des nouveaux corpus sera faite et à quel moment.
On rappelle que les trois autres équipes ont rendu toute cette pariet du travail et qu’on peut prendre tous les renseignements utiles auprès d’elles. Si ces engagements ne sont pas tenus, il faudrait recourir à d’autres solutions, que les responsables de Florence voudraient éviter.
APPENDIX 4 Main Communications from UPRO
José Deulofeu <jose.deulofeu@wanadoo.fr> sabato 2 marzo 2002 12.39 Chers amis, A) Je vous informe de la situation administrative des personnels travaillant pour CORAL ROM. 1) Magali Seijido Comme je vous l'annonçais dans mon précédent message, j'ai pu, après une longue discussion avec le nouveau responsable, vérifier que Magali remplit maintenant les conditions administratives pour qu'on puisse lui faire un contrat d'un an de jeune chercheur à partir du 1er Mars 2002. Elle aura un salaire net de 1200 € ce qui va permettre de lui payer le travail fait en fevrier. C'est vraiment une bonne conclusion inespérée et qui résout les problèmes immédiats. Le calendrier est le suivant : j'ai déposé la demande de contrat vendredi 1er Mars. Le contrat de travail devrait être signé dans une dizaine de jours. Je vous préviendrai dès que la signature sera donnée. 2) Sandra Bonnard : elle est engagée sur vacations comme Sandrine l'année dernière.Pas de problème. 3) EStelle Campione : pour elle il faudra une bourse gérée par Florence, comme nous l'avions prévu : elle ne peut pas être payée par la France. Comme elle est actuellement payée par l'université, sa bourse peut commencer seulement en juillet, si ça vous arrange. B) Modification du contrat UPRO. Nous avons la chance que le nouveau Président (élu en janvier) a nommé de nouveaux responsables de services plus jeunes et plus européens. Ils vont nous aider à remplir le maximum de notre contrat. Ils sont persuadés que ça nuirait à la réputation de l'université si on renonçait à une trop grande partie du montant de la bourse. Dans ce nouveau contexte, je vous propose de limiter le changement de contrat à deux points : 1) Le contrat pour Estelle, qui doit être géré directement par Florence. 2) L'augmentation demandée du poste "travel and subsistance" pour associer nos collègues d'autres universités (Paul, Bilger.) à la suite du travail. Nous pourrons assurer la mise à jour du concordancier. J'espère avoir été clair et utile. Bien cordialement José (vous avez peut-être reçu deux fois ce message, c'est une erreur)
Jean Veronis Jean.Veronis@newsup.univ-mrs.fr mercoledì 3 aprile 2002 9.55 Chers Collègues, J'ai le plaisir de vous annoncer que nous avons finalement pu recruter du personnel en nombre important, ce qui va nous permettre de rattraper notre retard dans les meilleurs délais. En fait, nous en avons d'ores et déjà rattrapé une bonne partie. Etant donné la taille que prend maintenant l'équipe qui travaille ici sur C-ORAL-ROM, nous avons convenu que j'en assurerai désormais l'entière direction scientifique et opérationnelle, tandis que José Deulofeu continuera à assurer la gestion financière. Afin de permettre la meilleure efficacité au sein de l'équipe, nous souhaiterions donc que l'interaction avec Florence et les autres partenaires se fasse désormais de façon organisée et centralisée, par mon intermédiaire. Je vous serai donc reconnaissant de bien vouloir désormais me faire parvenir toutes les informations touchant le projet. Je me chargerai de faire circuler ces informations au sein de l'équipe aixoise et de distribuer les tâches de façon que le plan de travail puisse être respecté. En ce qui concerne la réunion prévue ce week-end à Florence, nous en avons malheureusement été prévenus un peu tard, et nous ne sommes pas en mesure d'envoyer les spécialistes de prosodie de l'équipe, car ils ont déjà d'autres engagements à cette date. Nous n'aurions d'ailleurs pas été en mesure, en cette période de vacances universitaires pendant laquelle les services administratifs sont fermés, de faire acheter les billets et de faire donner une avance financière au personnel partant en mission. Notre université a une bureaucratie un peu lourde, et il faut faire connaître les missions au moins un mois à l'avance pour que les services administratifs puissent faire le nécessaire, surtout si des vacances interviennent entre temps. Vous savez l'intérêt que nous portons aux études prosodiques, et je vous serai toutefois très reconnaissant de bien vouloir me faire parvenir le compte-rendu de la réunion, que nous étudierons avec le plus grand soin. Je suis très heureux de voir que le projet est maintenant aussi bien engagé de notre côté, et j'en profite pour vous remercier de vos efforts incessants. A bientôt j'espère, Jean Véronis http://www.up.univ-mrs.fr/veronis/
Jean Veronis Jean.Veronis@newsup.univ-mrs.fr venerdì 3 maggio 2002 12.03 Chers Collègues, Comme nous vous l'avions annoncé, un nouveau président et de nouveaux Conseils dirigent depuis quelque temps notre université. Nous avons dû attendre que la nouvelle équipe soit opérationnelle pour pouvoir discuter efficacement des problèmes administratifs et financiers du contrat C-ORAL-ROM, ce que nous venons de faire. J'ai le plaisir de vous annoncer que la nouvelle équipe a été extrêmement positive à notre égard, et que nous avons pu résoudre toutes les difficultés de trésorerie et de personnel qui nous avaient malheureusement gênés la première année. Nous sommes donc en mesure d'embaucher tout le personnel nécessaire et de mener à bien la suite du projet sans changement contractuel. Nous vous remercions de vos démarches auprès de votre université pour la bourse post-doctorale, qui finalement n'est plus nécessaire. En ce qui concerne l'exécution du contrat, nous avons avancé de façon totalement satisfaisante et nous serons en mesure de vous remettre la totalité des données au format requis lors de la réunion de juin. Nous avons bien reçu vos nombreux messages et requêtes (fax, etc.), mais la plupart de nous semblent pas de nature contractuelle. Nous avons un contrat très clair avec la Commission Européenne, et nous honorerons ce contrat. Dans un souci d'efficacité et compte-tenu du retard, nous souhaiterions cependant ne pas avoir à nous disperser dans une bureaucratie lourde et de multiples interactions électroniques hors des cadres contractuels. Puis-je ajouter que j'ai été très surpris du ton autoritaire et agressif de vos divers messages, qui me paraît assez inhabituel par rapport aux projets interuniversitaires auxquels il m'a été donné de participer. Je souhaiterais, si c'est possible, que nous revenions à un esprit de bonne entente collaborative, qui me paraît tout à fait souhaitable et nécessaire pour la bonne marche de la suite du projet. Bien cordialement, Jean Véronis, Professeur Direteur de l'équipe DELIC
APPENDIX 5 Formal request to the President of UPRO
To the President of the “Université de Provence” 3, Place Victor Hugo 13331, Marseille France cc: Jean Veronis (Scientific person responsible of the C-ORAL-ROM project at UPRO) Giovanni Battista Varile (IST Program, Multimedia Contents and Tools, Head of Unit) Object: Request to fulfil the contractual obligations of the C-ORAL-ROM contract (IST 2000 26228)to the legal representative of the Université de Provence. Deliverables 1.1;1.2. Dear President, the above-mentioned Contract signed by the Université de Provence with the Commission foresees the delivery 1.1;1.2, by December 2001 (see pages 39 and 47 of Annex 1 to the Contract).
Despite many informal requests to the persons in charge at Description Linguistique
Informatizée sur Corpus (DELIC), which is the main Department carrying out the work at the Université de Provence (at Aix), we have not yet received the full contribution of UPRO for the deliverables; instead, to-date, we have only received some partial input which is far from that which is set forth in the Université de Provence contractual obligations. Attached to this letter, please find the Deliverable description reported to the Commission, in which the lacking portion of the work by the Université de Provence is detailed.
Therefore, on behalf of the C-ORAL-ROM Consortium, and in accordance with Article 7.3.b
of the Contract, we kindly request you to provide the co-ordinator with the above-mentioned deliverables 1.1 and 1.2 within one month of the receipt of this letter. Yours sincerely. Prof. Emanuela Cresti, Co-ordinator of the C-ORAL-ROM Project Dipartimento di Italianistica Università di Firenze Piazza. Savonarola, 1 50132 Florence Italy
APPENDIX 6 C-ORAL-ROM paper at LREC 2002
The C-ORAL-ROM Project. New methods for spoken language archives in a multilingual romance corpus Emanuela Cresti, Massimo Moneglia*, Fernanda Bacelar do Nascimento*, Antonio Moreno Sandoval*, Jean Veronis*, Philippe Martin*, Kalid Choukri, Valerie Mapelli*, Daniele Falavigna*, Antonio Cid*, Claude Blum*
* Dipartimento di Italianistica, Università di Firenze
*Centro de Linguistica da Universidade de Lisboa
Complexo Interdisciplinar, Av Gama Pinto, 2, 1649-003 Lisboa Portugal
*Laboratorio de Lingüística Informática Departemento de Linguistica, Universidad Autonoma de Madrid
Carretera de Colmenar Viejo Km 15 Cantoblanco 28049 Madrid Spain
*Description Linguistique Informatizée sur Corpus, Université de Provence
29, Avenue Robert Schuman13621 AIX EN PROVENCE - Cedex 1 France
European Language Association Agency (ELDA)
55-57, Rue Brillant-Savarin 75013 Paris France
Istituto Trentino di Cultura (Centro per la ricerca scientifica e tecnologica)
*Instituto Cervantes, Oficina del Español en la Sociedad de la Información
Livreros, 23 28801 Alcalà de Henares - Madrid Spain
Abstract
C-ORAL-ROM is a multilingual corpus of spontaneous speech of around 1.200.000 words representing the four main Romance languages: French, Italian, Portuguese and Spanish. The resource will be delivered in standard textual format, aligned to the audio source in a multimedia edition. C-ORAL-ROM aims to ensure both a sufficient representation of spontaneous speech variation in each language resource, and comparability among the four resources with respect to a definite set of variation parameters. The multimedia conception of C-ORAL-ROM allows simultaneously alignment and full appreciation of the acoustic information through the speech software WINPITCHCORPUS. The storage of spoken language resources is based on the identification of utterances in the four corpora through perceptively relevant prosodic properties. In C-ORAL-ROM, all the textual information is tagged simultaneously with respect to prosodic parsing and utterance limits. Each prosodic unit corresponding to an utterance is easily and directly aligned to its acoustic counterpart, thus ensuring a natural text - sound correspondence and the definition of a data base of possible speech acts in the four romance languages.
Florence1. The resource was set up during 2001 with a
1. Introduction
large reuse of corpora of spontaneous speech collected in
The main goal of the C-ORAL-ROM Project is to
previous academic studies (See Cresti, 2000; Bacelar do Nascimento, 2001; Lavacchi & Nicolas; 2000; Blanche-
provide a comparable set of corpora of spontaneous speech for the main Romance Languages, namely French,
Italian, Portuguese and Spanish (roughly 300,000 words
The C-ORAL-ROM Corpora will be delivered in the
same textual format following present EU standards
for each language). The project has been funded under the IST program of the EU and is being carried out by a
(EAGLE) in a multimedia edition on DVDs, integrated
European consortium co-ordinated by the University of
1 C-ORAL-ROM (IST 200026228). Official web site: http://lablita.dit.unifi.it/coralrom
with tools, assuring both concordances of the text and
verbs, but also that the relative frequency of nouns is
detailed analysis of the acoustic signal. The Corpus
much lower in informal conversations with respect to
edition will be associated with comparative linguistic
formal contexts (1/1 vs 1/3). Adjectives, on the contrary
studies, models and standard linguistic measures of
are much more frequent in formal speech.
spontaneous spoken language variabilit y. Publication and
In the domain of corpus based grammars, the
distribution for academic studies will be performed by
induction of the main syntactic properties is strongly
Champion, while ELDA will distribute the LR to speech
correlated to text variation parameters. For example in
English, both main types of dependent clauses (relative
The paper focuses on two features of the project that
and complement clauses) vary their relative frequency
according to socio -linguistic parameters. Generally
• sampling criteria adopted to ensure comparability
speaking, in syntactic structures controlled by a noun, the
frequency of both that-clauses and to-clauses is higher in
• the multimedia design of the C-ORAL-ROM
formal language, while, in verb-controlled structures,
that-clauses are much more frequent in conversation (Biber, 2000). Similar conclusions can be drawn with
2. Representation of spontaneous speech and
respect to relative clauses. Relative constructions are
comparability in a multilingual LR
much more frequent in formal speech, while the restrictive function is the more frequent, among relative clause
2.1. The representation issue
functions, in the all corpus variation (Biber et al., 1999). In other words, the pragmatic domain of corpora
The Spontaneous Spoken Language areas have
collection strongly influences the probability of
become consolidated only in quite recent times (See
occurrence of syntactic properties of spontaneous speech
Biber, 1988; Blanche-Benveniste, 1990; Cresti, 2000;
Givon, 1979; Miller & Weinert, 1999). Spontaneous
In between syntactic and lexical properties. It is
essential to the grammatical description of spoken
language to note that the majority of complement clauses
which depend on a verb, depend on a putandi verb in
(b) face-to-face dialogue in a large variety of
spontaneous conversation. However, such important data
are also relative to variation parameters. For example, a
(c) mental programming simultaneous with vocal
complement clause depends quite frequently on a dicendi
verb in broadcasting and media contexts (Biber et al.,
(d) contextually undetermined linguistic behaviour
Prosodic level. In the map tasking coding scheme
(Anderson et al., 1991), the set of possible dialogue acts,
The setting up of Spontaneous Speech databases is a
whose investigation is relevant to the link between
complex task. Spoken resources set up in controlled
prosodic and discourse structures, corresponds to roughly
environments (such as telephone information, health
16 possible moves in the map task (Stirling et al., 2001).
dialogues, map tasking) constitute at present the majority
On the contrary, current trends in corpora which document
of the databases used for the validation of language
a huge variety of socio -linguistic and pragmatic domains,
engineering. Their acoustic/phonetic quality is excellent,
show that the set of possible speech acts includes as many
but they deal with highly predictable semantic domains.
as 80 categories which are distributed all over the corpus
Should one wish to represent Spontaneous Speech in a
variation (Firenzuoli in preparation). Of course the
LR, the constitution criteria must ensure the widest
inductive data on the link between prosody and speech
possible variation in speech contexts, and a low control on
acts have a severe limitation in map tasking and need to be
the speech event, that is exactly the opposite of what
The study of prosody needs natural speech variations
There are many reasons for this necessity. Variability
for many reasons. For instance, quite surprisingly we
is the main property of spontaneous spoken texts. As a
noticed that thematic prosodic structures (topic/prefix
matter of fact, almost the complete set of linguistic levels
intonation see. 't Hart et al., 1990), largely characterised
of language description varies their quantitative weight a
formal texts, while the so called comma intonation
lot, when considered with respect to different pragmatic
(appendix/suffix 't Hart et al., 1990) strongly correlates to
everyday dialogues (Tizzanini in press).
Frequency lexicon level. The representation of a
Middle length of utterances (MLU). The demarcation
sufficient number of contexts covering, as far as possible,
of the utterances, is an essential data for the interpretation
relevant types of speech events in the universe, is the only
of natural speech and it turns out that such tagging level
possible strategy to identify significant frequency
allows the verification of important basic speech
lexicons. High frequency lexicon defined with respect to
measurements (Biber et al., 1999). In recent works (see
general corpora may be under-represented in specific
Tizzanini, in press; Rossi, 1999; Cresti, 2000, Moneglia,
pragmatic domains which on the contrary, by definition,
in press; Firenzuoli, 2000) has been verified, that MLU of
maximise the probability of occurrence of low frequency
texts marked by a strong degree of spontaneity (family
lexical items. That is the real point of interest for the rigid
conversations, country wakes, conversatio ns among work
definition of a semantic domain in the setting up of
colleagues and conversations among university students)
comparable corpora of dedicated resources.
systematically differs from MLU of formal texts
Syntactic level. It has been noted that in general
(university lectures and radio interviews).
corpora (Biber et al., 1999) nouns are more frequent than
Fig. 1 shows that the MLU is almost constant all
In the domain of speech, parallel corpora are possible only
through the contextual variation with the significant
exception of formal contexts, where we find a iato2.
Comparability is quite easy to pursue with respect to
The systematic correlation between type of contexts
resources based on the selection of a specific semantic
and MLU allows a strong quantitative prevision on the
domain (telephone information, health information, map
internal structure of the texts defining the probability of
tasking etc.) “people in the same controlled situation
the possible length of the utterance in each domain.
doing the same things”. However such resources are
acquired in a restricted series of situations and are
submitted to elicitation parameters (limited contexts) and therefore lack the main character of spontaneous speech (character d).
If we assume that the representation of spontaneous
speech must necessarily represent spoken text variation, in
a multilingual resource the more variability is represented
in each language resource, the more the language resource is difficult to compare with the other resources and
comparability is a function of the application of variation
C-ORAL-ROM sampling
The definition of significant variation parameters is,
therefore, a basic step towards the development of a comparable LR of spontaneous speech.
A long tradition of socio-linguistic studies (see Bilger,
1997; Labov, 1966; Biber, 1998; Berruto, 1987; Gadet,
1996) has frequently dealt with the significance of "socio-
situational parameters": 1) Socio-linguistic (age,
education, occupation, sex); 2) semiological (monologue,
dialogue, conversation); 3) sociological (family, public);
4) transmission (face-to-face, transmitted); 4) gender. In practice4.
Figure 1. Middle Length Average in text typologies
languages resources is based on the following set of
variation parameters that constitutes the semiological and
The representation of spontaneous speech must
therefore necessarily represent spoken text variation.
(a) Dialogical structure (monologues, dialogues,
2.2. The comparability issue
(b) Social domain of use (family; private life, public
The central problem which a multilingual corpus of
Spontaneous Speech must solve is the question of
comparability among different language resources in the
(e) Speaker parameters (Age, Sex, Education, and
Comparability in large Written Language Corpora
In C-ORAL-ROM, which has quite a limited
• Parallel corpora (for ex. CRATER and EUROROM)
dimension, such parameters are not uniformly verified
Corpora of the same type or of the same specialised
throughout all the variation. That should of course be
much better. In particular the use in the sampling strategy
of the formal / informal partition, which is absent in the
Clearly, with respect to the task of collecting
Dutch corpus, allows one to restrict the number of
Multilingual Spontaneous Spoken Language Corpora,
parameters under investigation reducing the set of possible
only the second alternative is, in principle, available. As a matter of fact, it is impossible to realise parallel corpora
variations, with low damage for representation purposes.
without losing the spontaneity characteristic (Character c).
In particular, text gender variation is the main criterion applied in the formal part, while social contexts of use and
dialogue structure variation are the variation parameters
2 From Cresti, 2000. Legend: TOT.Sampling: total data of sampling; TOT.FAM.: family typology; TOT.PRIV.free: private fee typology; TOT.PRIV.reg.: private regulate typology;
4 The Spoken Dutch Corpus (also under constitution at present)
TOT.PUB.free: public free typology; TOT.PUB.reg: public
is a concrete example of the use of such parameters in corpus
regulate typology; Media: mediatypology; Baby: baby talk
design (documentingthe Netherlands and Flanders). We were
not aware of the corpus design of the Dutch Corpus when the C-
3 The prototype example is the relation between the Brown
ORAL-ROM project was prepared (1999), but when sampling
Corpus (early 60’s, Brown University USA) and LOB Corpus
was decided (January 2001), its structure at
(Lancaster/Oslo/Bergen, 1970) which realise together a
http//lands/let.kun.nl/cgn/edesign.htm, confirmed the overall
comparable sampling of American English and British English.
systematically adopted for the informal part, where on the
contrary gender variation is not strictly defined as a
C-ORAL-ROM does not represent dia-topical phonetic
variations. In a multilingual collection dia-topical limits for each language must be established. Corpora are
collected in Continental Portugal, Central Castilia Spain,
Southern France, Western Tuscany, and are intended to
represent some possible standard, rather than all the
varieties of pronunciation, which need collections of interlinguistic corpora with a wide dia-topical variation5.
Therefore, each corpus does not represent phonetic
variation, but rather is expected to demonstrate a sufficient
variation across language uses for at least studying
communicative acts, lexicon, syntax and prosody.
The main choices adopted in C-ORAL-ROM for the
representation of speech variability in four 300.000 word
splitting formal speech (50%) and informal speech (50%), variation ensuring a sufficient representation
of dialogical Informal Speech (which is the resource
• selecting distinct criteria for sampling the formal and
• defining a text weight ( from 1500 to 3000 words for
each text ) that ensures both the possible appreciation
of macro-textual properties and sufficient
representation of the universe in each 300.000 word
• representing a variety of possible recording situations
within the range of perception and intelligibility of the human ear 6.
recording as part of the meta-data: a) Speaker characteristics; (gender, age, geographical region education and occupation); b) acoustic quality of the
As a consequence of those choices, each corpus in the
multilingual resource cannot be said to be comparable to
the others with respect to specific semantic domains, but
The comparable Romance Spoken Corpus is identified
rather, with respect to the possible occurrence of spoken
by means of common Sampling criteria, and the same
language structure/s at both syntactic and prosodic levels
proportion of each type in the four corpora: the following
in a variety of possible significant contexts.
are the tables for the formal and informal part of each Romance corpus in the C-ORAL-ROM resource.
Textual format
The four Romance Corpora have been transcribed or
converted into standard textual format (Gibbon et al., 1997).The format definition of spoken texts involves: 1)
dialogue representation; 2) text co-ordinates; 3) prosodic
tagging. The C-ORAL-ROM textual format is defined as
an implementation of the CHAT architecture (Mac
a) Heading, containing a definite set of meta-textual
b) Text lines in orthographic transcription divided as
c) vertically, in dialogic turns (introduced by a speaker
d) horizontally, by prosodic parsing and utterance limit,
5 This limitation is quite severe for Italian, where local varieties
representing terminal and non terminal prosodic
may strongly diverge from the standard (De Mauro et al., 1993)
6 The sound files of the acoustic database are set on a quality scale (recording, volume, voice overlapping and noise) and are
comparable with respect to it. The quality scale extends from the
8 10 long samples 4.500w; at least 64 short sample, 1500w;
highest level of clarity of the voice signal to low levels of
7.500w collections of very short dialogues in public context
acoustic quality. The quality is gauged spectrographically.
9 2 or 3 sample for each gender of 3000 words average with only
7 At least 23.000 conversations with more then two participants
e) Dependent tiers for context information and possible
mouse clicking as slowed speech is perceived, and
automatically building an aligned text database (up to 8
layers of text annotation and alignment). It incorporates a
The C-ORAL-ROM textual Corpus will turns out
mouse driven file segmentation tools, with precise time
tagged with respect to: a) utterances corresponding to
adjustment on on-screen speech spectrogram and prosodic
speech acts (Austin, 1962; Cresti, 1994 and 2000); b)
parameters display. This allows a fast and precise
prosodic parsing of each utterance (’t Hart et al., 1990);
segmentation of both long prosodic units (utterances) and
c) words vs. word fragments distinction; d) overlapping.
small speech units such as syllables or phones. Among its numerous features:
3. Multimedia
a) Recording, and playback of long signals (memory
limited) at standard sampling rates (8,000 Hz, 11,025
The definition of the text to speech interface in C-
ORAL-ROM is based on the idea that the access to
Hz, 16,000 Hz, 22050 Hz, 32,000 Hz, 44,000 Hz and
acoustic information in a multimedia corpus (alignment)
64,000 Hz) in mono or stereo mode, at 8 bit or 16 bit encoding;
must go hand in hand with the representation of prosody. Such a method can be proposed as a possible standard for
b) Standard black and white and color spectrogram of
storing oral language in multimedia and multi-modal
any part of the speech signal, with 3 distinct zooming tools (down to 1 sample resolution), 8 levels of
language resources. C-ORAL-ROM will ensure simultaneously:
bandwidth and 8 available analysis windows, 3
a) tagging with respect to prosodic parsing & action
c) Powerful fundamental frequency and intensity
b) acoustic analysis with special functions for F0
analysis (3 standard methods – spectral comb,
AMDF, harmonic selection) with all user adjustable parameters;
c) Utterance-based text - speech alignment
d) Prosodic morphing, user graphically defined
3.1. Acoustic format
modification of the prosodic parameters of natural speech (fundamental frequency, intensity, syllable
C-ORAL-ROM comes from the reuse of previously
established resources recorded with various analogue or
e) Easy insertion of text, bookmarks, comments. User
digital equipment and from new recordings. The following
are the requirements for the acoustic format:
Format: mono or stereo .wav files (Windows PCM),
WinPitch also complies with the MDI Windows
standard (Multiple Document Interface), and allows all
Recording and storing process for old Analogue
functions to be concurrently applied to multiple speech
recording: directly derived in wav files (20.050 hz 16
bit) from the original analogue tapes through a standard sound card (Sound Blaster live or compatible) with a
3.3. Alignment units Recording and storing process for new recording:
The storage of spoken language resources should be
a) dialogues: stereo DAT or minidisk recording
based on the selection of a natural alignment unit. In C-ORAL-ROM all the textual information is tagged
(44.100Hz) with two unidirectional Micro-phones, converted into mono or stereo .wav files (Windows PCM,
simultaneously with respect to prosodic parsing and
22050Hz, 16 bit) via SPDIF port of a standard sound card
utterance limits, therefore, each prosodic unit corresponding to an utterance can be easily and directly
(Sound Blaster live or compatible) with a professional sound editor
aligned to its acoustic counterpart, thus ensuring a natural
b) conversations with more than two participants:
and meaningful text - sound correspondence.
This step is quite controversial at two levels. It implies
mono DAT or minidisk recording with cardioid or omni-directional microphone converted into mono .wav files
on the one hand that the notion of utterance should be
(Windows PCM, 22050Hz, 16 bit) via SPDIF port of a
preferred to other possible linguistic notions as a natural alignment unit and that, on the other hand, the criteria for
standard sound card (Sound Blaster live or compatible) with a professional sound editor.
the identification of utterances in a spoken language corpus are reliable.
3.2. WinPitchCorpus
As far as the first question is concerned word based alignment (that has been preferred for example in the
In synthesis the function of the Align Programme in C-
Spoken Dutch Corpus) has low significance in
ORAL-ROM is to orient the sound signal exploitation
spontaneous speech, and it is hard to be pursued for
allowing, not only the transit from text to sound, but also,
prosodic reasons. In spontaneous spoken language words
are co-articulated in prosodic units and the acoustic effect
Text -speech alignment and acoustic analysis are
of a word-based alignment is perceptively unnatural.
ensured through the speech software WinPitchCorpus
Moreover, the alignment becomes significant from a
linguistic point of view once it is defined with respect to a
WinPitchCorpus (see http://www.winpitch.com) is a
compositional linguistic domain, that is ranked over the
general purpose speech analysis tool working under
word level description. Therefore, the alignment problem
Windows 2000/XP with many functions devoted to the
is linked to the definition of the language structure in the
alignment and annotation of large corpora. In particular,
Text -speech aligner tool, is based on a user adjustable speech slow-down process, in order to easily select text by
The C-ORAL-ROM approach is based on the idea that
weak and too strong for the representation of natural
while Written language is characterised by a textual
speech and, moreover, it does not allow any prevision on
organisation based on syntax, Spoken language is mainly
spoken corpora segmentation even from a statistic point of
characterised by utterances, having a pragmatic nature and
corresponding to communicative acts (Quirk, et al., 1985; Biber, et al., 1999; Cresti, 2000). In facts, sentence based
Prosodic tagging
(or clause based) alignment turns out to be strongly
The segmentation of spoken texts into utterances
underdetermined in spontaneous spoken texts. For
corresponding to speech acts can be based on prosodic
example, considering textual information, the following
properties that are highly identifiable at the perceptual
dialogic turn is apparently one sentence:
In C-ORAL-ROM the prosodic tagging of the
transcribed text is not a transcription of the intonation, as
for example ToBi, or MARSEC that specifies the
%sit: in a garage, a secretary looking for some
intonation profiles according to a phonological typology.
In C-ORAL-ROM prosodic tagging specifies on the text
each perceptively relevant prosodic break in the speech
On the contrary the relevant acoustic information
reveals that the dialogic turn is compound of two
utterances, which can receive the following paraphrases:
a) Tone units with a non terminal contour, reported
"I wander which kind of car this one is. Is it a Punto ?" .
every time a non terminal prosodic break can be
In other words, the two utterances define two
perceived in a word sequence by a competent
meaningful units for a linguistically relevant alignment,
while the syntactic approach will lead to a meaningless
b) Terminal contours (utterance limit) reported every
alignment from a linguistic point of view.
time that a terminal prosodic break can be perceived
Therefore textual information does not determine a
by a competent speaker: // ? (double slash or
significant alignment unit in spoken language, in which
not textual information is frequently required and, as the
previous example shows, a meaningful alignment unit
The previous example will be transcribed as follows in
may not have a clause or sentence structure. So
syntactically based alignment is at least underdetermined.
The relevant linguistic events (utterances) must be
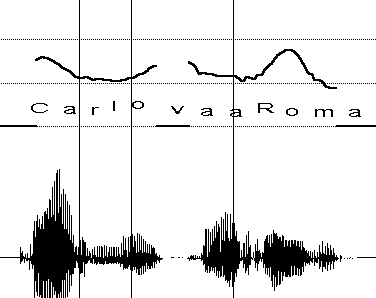
*SEC: che macchina l’è / codesta // Punto ?
selected in the speech continuum through the full
appreciation of the acoustic and pragmatic information.
%sit: in a garage, a secretary looking for some
This conclusion, however, leads us to the second question.
A definition of utterance as a speech continuum from one silence to another silence has been frequently
Crucially, terminal breaks indicate the prosodic
proposed, even as an objective mark allowing the
automatic detection of utterance limits on the acoustic
signal. However it must be stressed that the notion of
The definition of utterance in C-ORAL-ROM is
utterance as a speech continuum from one silence to
theoretically defined. Given that intonation parses the
another silence is both too week and too strong for the
speech continuum with relevant F0 movements, we
representation of natural speech and therefore it does not
assume that the identification of utterances in the sound
allow any prevision on spoken corpora segmentation. In
continuum is linked to the detection of perceptively
particular we can highlight the following:
relevant F0 movements. Also very traditional studies of
prosody have noted that there is no such thing as an
a) segments of sound wave that are between two sound
utterance without a profile of terminalintonation
(Karcevsky, 1931; Crystal, 1975). Therefore the
b) in spontaneous speech frequently utterances start
systematic correlation between terminal contours and
and/or stop with no break in the sound wave.
utterance limit is an efficient heuristic method for speech
The quantitative relevance of both properties in
However, at the theoretical level, we must consider
spontaneous speech cannot be stated with precision but
that perception is highly sensitive to voluntary F0
only guessed. For example from 20% to 50% of
variation (’t Hart et al., 1990) and that every utterance in
utterances (depending on the text gender) of spontaneous
spoken language on the one hand is the voluntary
speech corpora have a topic unit (Signorini, 2001). A topic
accomplishment of a speech act (Austin, 1962) and on the
cannot be an utterance but is frequently in between two
other, it is necessarily parsed in one or more tone units.
The background theory of the C-ORAL-ROM project
Similarly the second utterance of the previous example
(Cresti, 1994, 2000) links the two properties: the
is not preceded by a temporal break. The frequency of
voluntary F0 variations do not simply scan the utterance,
new utterances that start with no temporal break (or less
but rather express functional values that are necessary to
than the voiceless part of a stop consonant) has not be
the accomplishment of speech acts. For this reason the
counted but it is of course a very high percentage in
selection of textual units corresponding to an utterance
can be based on prosodic properties. In particular, as we
In conclusion, the notion of utterance as a speech
did in the previous example, it is possible to identify an
continuum from one silence to another silence is both too
utterance each time the prosody makes it possible to
perceive the completion of a speech act; i.e. intonation
Bacelar do Nascimento, F., (ed.), 2001. Portugues falado:
permits the pragmatic interpretation of the text
varietades geograficas e sociais, Lisboa: CLUL &
illocutionary criterion has been successfully applied to
Bally, C.,1950. Linguistique générale et linguistique
both the corpora of Adult Spontaneous Speech and Infant
française, Berne: Francke Verlag.
Speech allowing their tagging in utterances (see. Moneglia
Berruto, G., 1987. Sociolinguistica dell’Iitaliano
The identification of functional values for prosody is
Biber, D., 1988. Variation across speech and writing,
also in some sense traditional (Bally, 1950; Halliday,
1985). For example, it has been noted that, within the
Biber, D., S. Johansson, G. Leech, E. Finegan (eds.) 1998.
possible tone units, the tone information which enables
Corpus linguistics: investigating language structure
one to identify the illocution, or modality, of the utterance
and use. Cambridge: Cambridge University Press.
lies in a specific scansion unit (Martin, 1978).
Biber D., S. Johansson, G. Leech, S. Conrad, E. Finegan
The theoretical approach we are referring to
(eds.) 1999, The Longman grammar of spoken and
systematically links the study of such values to the study
written English . London: Longman.
of spontaneous speech. The melodic pattern which scans
Biber D. 2000. Corpus based analysis of grammar:
an utterance can be simple (composed of a single tone
variability in the form and use of English complement
unit) or complex (in which case it is made up of two or
clauses. In M. Bilger (ed.), Corpus, Methodologie et
more tone units linked melodically together).
applications linguistique. Paris: Champion, 224-237.
Non terminal tone units correspond to the scanning of
Bilger, M. , 1997. Corpus de portugais & d’espagnol.
an utterance by means of a complex pattern: the type of
Revue de l’Association Français de linguistique
which is discriminated at the perceptual level on the base
of its form (intonation pattern , 't Hart, et al., 1990). In
Blanche-Benveniste, C. (ed.), 1990. Le français parlé:
principle each perceptively relevant tone unit conveys a
ètudes grammaticales . Paris: Editions du CNRS.
specific functional value (informational patterning; see
Blanche-Benveniste, C. (ed.) in press. Corpus du
Cresti, 1994; Crest & Firenzuoli in press). For example,
Français parlé. Echantillonages. Paris: Champion.
the first tone unit of the following utterance is a Topic
Cresti, E., 1994. Information and intonational patterning
(prefix contour) and is followed by an information unit
in Italian. In B. Ferguson, H. Gezundhajt, Ph. Martin
(with a root contour) allowing the identification of the
illocutionary value of the utterance (Comment).
phonologiques. Toronto: Editions Mélodie. 99-140.
Cresti, E., 2000. Corpus di italiano parlato, vol. I- II, CD-
Cresti, E., V. Firenzuoli in press. L’articolazione
informativa topic-comment e comment-appendice: correlati intonativi, In Atti delle XII° GFS (Macerata 15 Dicembre 2001). Macerata: Università di Macerata Press.
Crystal, D., 1975. The English tone of voice, London
De Mauro, T., F. Mancini, M. Vedovelli, M. Voghera
1993. Lessico di frequenza dell'italiano parlato. Milano: Etass Libri.
Firenzuoli, V., 2000. Nuovi dati statistici sull’italiano
parlato. Romanische Forshungen, 13: 213-225.
Firenzuoli, V., in preparation. Repertorio dei profili
The results obtained on the basis of the application of
intonativi di valore illocutivo in un corpus di italiano
the illocutionary criterion are crucially confirmed in the
parlato, Ph.D. thesis, Firenze: LABLITA.
macro-syntactic theory of spoken language (Blanche-
Gadet, F., 1996. Variabilité, variation, varieté: le Français
Benveniste, 1990) for which the syntactic noyau coincides
d’Europe. French Language Studies, 6:45-58.
with the tone unit bearing the illocutionary value.
Gibbon, D., R. More, R. Winski (eds.), 1997. The
C-ORAL-ROM Corpora represent the variety of
handbook of Standards and Resources for Spoken
speech acts performed in everyday language use and
language Systems. Berlin: Mouton & de Gruyter.
enables the description of their prosodic and syntactic
Givon, T. (ed.), 1979. Discourse and Syntax. In Givon T.
structure in the four Romance Languages, from a
(ed.), Syntax and Semantics, vol. 12. New York:
quantitative and qualitative point of view.
Halliday, M., 1985. Spoken and written languages.
4. References
Austin, L.J., 1962. How to do things with words, Oxford:
’t Hart, H., R. Collier, A. Cohen, 1990. A perceptual study on intonation. An experimental approach to speech
Anderson, A., M. Bader, E. Bard, E. Boyle, G. Doherty,
melody. Cambridge: Cambridge University Press.
S. Garrod, S. Isard, J. Kowtko, J. McAllister, J.
Karcevsky, S., 1931. Sur la phonologie de la phrase, in
Miller, C. Sotillo, H. Thompson, R. Weinert, 1991.
Travaux du Cercle linguistique de Prague, IV.
The HCRC map task corpus. Language and Speech, 34:
Labov, W., 1966. The social stratification of English in
Lavacchi, L., C. Nicolas, 2000. Dizionario Spagnolo Italiano, (CD-rom Edition). Firenze: Le Lettere.
MacWhinney, B., 1994. The CHILDES project: tools for
Martin, Ph. 1978. Questions de phonosyntaxe et de
Miller, J. & Weinert, R. 1999., Spontaneous Spoken language, Oxford: Clarendon Press.
Moneglia, M., in press. I corpora dell’italiano parlato di
LABLITA: Criteri di costituzione, unità di analisi e comparabilità dei dati linguistici orali. In E. Burr (ed.), Atti del VII° Convegno internazionale SILFI. Pisa: Cesati.
Moneglia, M., E. Cresti, 1997. Intonazione e criteri di
trascrizione del parlarto, in U. Bortolini E. Pizzuto (eds), Il progetto CHILDES Italia, Pisa: Del Cerro.
Miller, J., R. Weinert, 1999. Spontaneous Spoken language . Oxford: Clarendon Press.
Quirk, R., S. Greenbaum, G. Leech, J. Svartvik, 1985. A comprehensive Grammar of the English Language. London: Longman.
Rossi, F., 1999. Le parole dello schermo . Roma: Bulzoni. Signorini, S., 2001. Caratteristiche sintattiche e frequenze dei topic in un corpus di parlato italiano, Tesi di Laurea, Univerity of Florence.
Stirling, J., I. Fletch.r, R. Mushin, L. Wales, 2001.
Representational issues in annotation: Using the Australian map task corpus to relate prosody and discourse structure. Speech Communication, 33:113-134.
Tizzanini, G., in press. L’articolazione dell’informazione.
Dati quantitativi di un corpus di italiano parlato. In E. Burr (ed.), Atti del VII° Convegno internazionale SILFI, Pisa: Cesati.
APPENDIX 7 CV New manager CURRICULUM VITAE Eng. Marius Bogdan SPINU Ph.D
PERSONAL DATA:
• Place of birth: Vatra Dornei (Romania) ; Date: 03.20.1970 • Civil status: married. • Residence: via Favini 47, PRATO 59100, Italy • Phone: 055 4796365, 347.3182020 (mobile) • E-mail: spinu@lablita.dir.unifi.it or: spinu@dsi.unifi.it
EDUCATION:
• 2002: Receive the Ph.D in Computer Science and Telecommunication from the University
of Florence, Italy with a thesis on Watermarking music scores, transaction model for digital music distribution
• 1998: Receive the degree in Telecommunication Engineering from the University of
• 1988: High school "Stefan Cel Mare", Suceava, Romania
COMPUTER SKILLS:
• Object-Oriented and structured programming
§ Pascal, C, C++ , Assembler80x86, HTML, Perl, ASP, CGI, JScript
• Operating systems: MS-DOS,Windows(NT, 3.x, 9x, 2000),Unix and unixlike (Linux) • Other:
§ Personal Computer components (characteristics, installing) § Computer architecture (microprocessors, memories, microcontrollers)
LANGUAGES:
• Romanian (native tongue). • Italian (very well). • English (well). • French (quite good).
WORK EXPERIENCES:
1988-1989 mechanic in a Romanian enterprise
1998-1999 hardware/software technician at Centro HL in Florence
1999-2000 Excel teacher at CESIT Florence
from 1998 consultant for several software house in Florence
from 1999 scientific consultant at "Dipartimento di Sistemi e Informatica" at Florence
University working also for: • European ESPRIT MOODS project
• Protection techniques for IPR on music delivering field
from 2000 "Technological aspects in using the computer" teacher for CESCOT Toscana
• dicembre 1998 - febbraio 2000: EXETICA S.r.l. Firenze (via Cavour 8, 50129, Firenze)
• October 1999 – April 2000: realisation of a CD-ROM for Siderfor S.r.l. (viale Unità d'Italia
105/107, 57025, Piombino -LI-) inside the Campus "Multimedia" project
• December 1999 - January 2000: Consultant to l'AGENZIA PER L'ALTA TECNOLOGIA
CESVIT S.p.A., Via G. del Pian dei Carpini, 28) for an ESPRIT project proposal (for Provincia di Ascoli Piceno)
• October 2000 – June 2001: Engineering Ingegneria Informatica (Via G. del Pian dei Carpini,
1, Firenze) for teaching, software and web applications development
• From February 2002: Contract teacher to the University of Florence for Microprocessor systemscourse at the Faculty of Information Engineering CONFERENCES:
• In the “technical committee” of International Conference on Software Maintenance ICSM2001
• In the “technical committee” of Web Delivering of Music WEDELMUSIC2001
• In the “technical committee” of Web Delivering of Music WEDELMUSIC2002 PUBLICATIONS: International Journals:
• P. Bellini, F. Fioravanti, P. Nesi, M. B. Spinu, "Cooperative Visual Manipulation of
Music Notation" Submitted to ACM transaction on Human Computer Interaction.
Italian Journals:
• P. Bellini, I. Bruno, R. Della Santa, P.Nesi, M. Spinu, "Musica e Internet, Distribuzione e Fruizione", Scienza&Business nr. 1 -2/2001, (2001). International Conferences:
• M. Monsignori, P. Nesi, M. B. Spinu, "A high capacity technique for watermarking music sheet while printing". In proc. of MMSP2001 (pp. 493-498), October 3 -5, 2001, Cannes (France)
• M. Monsignori, P. Nesi, M. B. Spinu, "Watermarking music sheet"
In proc. of PCM2001 (The Second IEEE Pacific-Rim Conference on Multimedia) (pp. 646-653) , October 24-26, 2001, Beijing (China)
• M. Monsignori, P. Nesi, M. B. Spinu, "Watermarking music sheet while printing"
In Proc. of WEDEL2001 (pp. 28-35), November, 23-24, 2001, Florence
• C.Busch, P.Nesi, M.Schmucker, M.B.Spinu “Evolution of MusicScore Watermarking
Algorithm”, Accepted to SPIE 2002, 20–25 January 2002, San Jose, California USA.
Italian Conferences:
• P. Bellini, I. Bruno, R. Della Santa, P.Nesi, M. Spinu, "Music Distribution and Protection", In proceedings of the Electronic Imaging & the Visual Arts, EVA2001 conference, March, 26-30, 2001, Florence (Italy)
• P. Bellini, I. Bruno, R. Della Santa, P.Nesi, M. Spinu "Safe distribution of multimedia musical objects". In proc. of AICA2001 congress (pg. 101-112), September, 19-21, 2001, Como (Italy)
• P. Bellini, I. Bruno, R. Della Santa, P. Nesi, M. B. Spinu "A Format for Modelling and
Managing Integrated Musical Objects". In proc. of AIIA2001 – 7th Conference of the Italian Association for Artificial Intelligence.
Your GP or Endocrinologist may also check: What do I need to know about my medication? Hypoparathyroidism The aim of treatment is to abolish symptoms – not to restore ‘normal’ calcium levels in the blood. In the absence of PTH, higher levels of calcium are found in the urine for a given blood calcium level. When hypoparathyroidism occurs as a complication This can caus
Institución Educativa Escuela Normal Superior Resolución Aprobación Nro.006990 de Sept.07/92 Acreditación MEN Resolución Nro. 3684 de Dic. 09/98 INSTITUCIÓN EDUCATIVA ESCUELA NORMAL SUPERIOR MARÍA AUXILIADORA INFORME DE GESTIÓN VIGENCIA 2011 Copacabana, febrero 16 de 2012 Presentación Hna Sara Cecilia Sierra Jaramil o, con Cédula de ciudadanía Nº 42 679 309, del munici
 perceive the completion of a speech act; i.e. intonation
Bacelar do Nascimento, F., (ed.), 2001. Portugues falado:
permits the pragmatic interpretation of the text
varietades geograficas e sociais, Lisboa: CLUL &
illocutionary criterion has been successfully applied to
Bally, C.,1950. Linguistique générale et linguistique
both the corpora of Adult Spontaneous Speech and Infant
française, Berne: Francke Verlag.
Speech allowing their tagging in utterances (see. Moneglia
Berruto, G., 1987. Sociolinguistica dell’Iitaliano
The identification of functional values for prosody is
Biber, D., 1988. Variation across speech and writing,
also in some sense traditional (Bally, 1950; Halliday,
1985). For example, it has been noted that, within the
Biber, D., S. Johansson, G. Leech, E. Finegan (eds.) 1998.
possible tone units, the tone information which enables
Corpus linguistics: investigating language structure
one to identify the illocution, or modality, of the utterance
and use. Cambridge: Cambridge University Press.
lies in a specific scansion unit (Martin, 1978).
Biber D., S. Johansson, G. Leech, S. Conrad, E. Finegan
The theoretical approach we are referring to
(eds.) 1999, The Longman grammar of spoken and
systematically links the study of such values to the study
written English . London: Longman.
of spontaneous speech. The melodic pattern which scans
Biber D. 2000. Corpus based analysis of grammar:
an utterance can be simple (composed of a single tone
variability in the form and use of English complement
unit) or complex (in which case it is made up of two or
clauses. In M. Bilger (ed.), Corpus, Methodologie et
more tone units linked melodically together).
applications linguistique. Paris: Champion, 224-237.
Non terminal tone units correspond to the scanning of
Bilger, M. , 1997. Corpus de portugais & d’espagnol.
an utterance by means of a complex pattern: the type of
Revue de l’Association Français de linguistique
which is discriminated at the perceptual level on the base
of its form (intonation pattern , 't Hart, et al., 1990). In
Blanche-Benveniste, C. (ed.), 1990. Le français parlé:
principle each perceptively relevant tone unit conveys a
ètudes grammaticales . Paris: Editions du CNRS.
specific functional value (informational patterning; see
Blanche-Benveniste, C. (ed.) in press. Corpus du
Cresti, 1994; Crest & Firenzuoli in press). For example,
Français parlé. Echantillonages. Paris: Champion.
the first tone unit of the following utterance is a Topic
Cresti, E., 1994. Information and intonational patterning
(prefix contour) and is followed by an information unit
in Italian. In B. Ferguson, H. Gezundhajt, Ph. Martin
(with a root contour) allowing the identification of the
illocutionary value of the utterance (Comment).
phonologiques. Toronto: Editions Mélodie. 99-140.
Cresti, E., 2000. Corpus di italiano parlato, vol. I- II, CD-
Cresti, E., V. Firenzuoli in press. L’articolazione
informativa topic-comment e comment-appendice: correlati intonativi, In Atti delle XII° GFS (Macerata 15 Dicembre 2001). Macerata: Università di Macerata Press.
Crystal, D., 1975. The English tone of voice, London
De Mauro, T., F. Mancini, M. Vedovelli, M. Voghera
1993. Lessico di frequenza dell'italiano parlato. Milano: Etass Libri.
Firenzuoli, V., 2000. Nuovi dati statistici sull’italiano
parlato. Romanische Forshungen, 13: 213-225.
Firenzuoli, V., in preparation. Repertorio dei profili
The results obtained on the basis of the application of
intonativi di valore illocutivo in un corpus di italiano
the illocutionary criterion are crucially confirmed in the
parlato, Ph.D. thesis, Firenze: LABLITA.
macro-syntactic theory of spoken language (Blanche-
Gadet, F., 1996. Variabilité, variation, varieté: le Français
Benveniste, 1990) for which the syntactic noyau coincides
d’Europe. French Language Studies, 6:45-58.
with the tone unit bearing the illocutionary value.
Gibbon, D., R. More, R. Winski (eds.), 1997. The
C-ORAL-ROM Corpora represent the variety of
handbook of Standards and Resources for Spoken
speech acts performed in everyday language use and
language Systems. Berlin: Mouton & de Gruyter.
enables the description of their prosodic and syntactic
Givon, T. (ed.), 1979. Discourse and Syntax. In Givon T.
structure in the four Romance Languages, from a
(ed.), Syntax and Semantics, vol. 12. New York:
quantitative and qualitative point of view.
Halliday, M., 1985. Spoken and written languages.
4. References
perceive the completion of a speech act; i.e. intonation
Bacelar do Nascimento, F., (ed.), 2001. Portugues falado:
permits the pragmatic interpretation of the text
varietades geograficas e sociais, Lisboa: CLUL &
illocutionary criterion has been successfully applied to
Bally, C.,1950. Linguistique générale et linguistique
both the corpora of Adult Spontaneous Speech and Infant
française, Berne: Francke Verlag.
Speech allowing their tagging in utterances (see. Moneglia
Berruto, G., 1987. Sociolinguistica dell’Iitaliano
The identification of functional values for prosody is
Biber, D., 1988. Variation across speech and writing,
also in some sense traditional (Bally, 1950; Halliday,
1985). For example, it has been noted that, within the
Biber, D., S. Johansson, G. Leech, E. Finegan (eds.) 1998.
possible tone units, the tone information which enables
Corpus linguistics: investigating language structure
one to identify the illocution, or modality, of the utterance
and use. Cambridge: Cambridge University Press.
lies in a specific scansion unit (Martin, 1978).
Biber D., S. Johansson, G. Leech, S. Conrad, E. Finegan
The theoretical approach we are referring to
(eds.) 1999, The Longman grammar of spoken and
systematically links the study of such values to the study
written English . London: Longman.
of spontaneous speech. The melodic pattern which scans
Biber D. 2000. Corpus based analysis of grammar:
an utterance can be simple (composed of a single tone
variability in the form and use of English complement
unit) or complex (in which case it is made up of two or
clauses. In M. Bilger (ed.), Corpus, Methodologie et
more tone units linked melodically together).
applications linguistique. Paris: Champion, 224-237.
Non terminal tone units correspond to the scanning of
Bilger, M. , 1997. Corpus de portugais & d’espagnol.
an utterance by means of a complex pattern: the type of
Revue de l’Association Français de linguistique
which is discriminated at the perceptual level on the base
of its form (intonation pattern , 't Hart, et al., 1990). In
Blanche-Benveniste, C. (ed.), 1990. Le français parlé:
principle each perceptively relevant tone unit conveys a
ètudes grammaticales . Paris: Editions du CNRS.
specific functional value (informational patterning; see
Blanche-Benveniste, C. (ed.) in press. Corpus du
Cresti, 1994; Crest & Firenzuoli in press). For example,
Français parlé. Echantillonages. Paris: Champion.
the first tone unit of the following utterance is a Topic
Cresti, E., 1994. Information and intonational patterning
(prefix contour) and is followed by an information unit
in Italian. In B. Ferguson, H. Gezundhajt, Ph. Martin
(with a root contour) allowing the identification of the
illocutionary value of the utterance (Comment).
phonologiques. Toronto: Editions Mélodie. 99-140.
Cresti, E., 2000. Corpus di italiano parlato, vol. I- II, CD-
Cresti, E., V. Firenzuoli in press. L’articolazione
informativa topic-comment e comment-appendice: correlati intonativi, In Atti delle XII° GFS (Macerata 15 Dicembre 2001). Macerata: Università di Macerata Press.
Crystal, D., 1975. The English tone of voice, London
De Mauro, T., F. Mancini, M. Vedovelli, M. Voghera
1993. Lessico di frequenza dell'italiano parlato. Milano: Etass Libri.
Firenzuoli, V., 2000. Nuovi dati statistici sull’italiano
parlato. Romanische Forshungen, 13: 213-225.
Firenzuoli, V., in preparation. Repertorio dei profili
The results obtained on the basis of the application of
intonativi di valore illocutivo in un corpus di italiano
the illocutionary criterion are crucially confirmed in the
parlato, Ph.D. thesis, Firenze: LABLITA.
macro-syntactic theory of spoken language (Blanche-
Gadet, F., 1996. Variabilité, variation, varieté: le Français
Benveniste, 1990) for which the syntactic noyau coincides
d’Europe. French Language Studies, 6:45-58.
with the tone unit bearing the illocutionary value.
Gibbon, D., R. More, R. Winski (eds.), 1997. The
C-ORAL-ROM Corpora represent the variety of
handbook of Standards and Resources for Spoken
speech acts performed in everyday language use and
language Systems. Berlin: Mouton & de Gruyter.
enables the description of their prosodic and syntactic
Givon, T. (ed.), 1979. Discourse and Syntax. In Givon T.
structure in the four Romance Languages, from a
(ed.), Syntax and Semantics, vol. 12. New York:
quantitative and qualitative point of view.
Halliday, M., 1985. Spoken and written languages.
4. References